


Too Hot for Academic Journals: Lexical Diversity and Quality in L1 and L2 Student Essays

Today I'm printing a pilot study I wrote as a seminar paper for one of my PhD classes, a course in researching second language learning. It was one of the first times I did what I think of as real empirical research, using an actual data set. That data set came from a professor friend of mine. It was a corpus of essays written for a major test of writing in English, often used for entrance into English-language colleges and universities, and developed by a major testing company. The essays came packaged with metadata include the score they received, making them ideal for investigating the relationship between textual features and perceived quality, then as now a key interest of mine. And since the data had been used in real-world testing with high stakes for test takers, it added obvious exigence to the project. The data set was perfect - except for the very fact that it was from Big Testing Company, and thus proprietary and subject to their rules about using their data.
That's why, when I got the data from my prof, she said "you probably won't want to try and publish this." She said that the process of getting permission would likely be so onerous that it wouldn't be worth trying to send it out for review. That wasn't a big deal, really - like I said, it was a pilot study, written for a class - but this points to broader problems with how independent researchers can vet and validate tests that are part of a big money, high-stakes industry.
Here's the thing: often, to use data from testing companies like Big Testing Company, you have to submit your work for their prior review at every step of the revision process. And since you will have to make several rounds of changes for most journals, and get Big Testing Company to sign off on them, you could easily find yourself waiting years and years to get published. So for this article I would have had to send them the paper, wait months for them to say if they were willing to review it and then send me revisions, make those revisions and send the paper back, wait for them to see if they'd accept my revisions, submit it to a journal, wait for the journal to get back to me with revision requests, make the revisions for the journal, then send the revised paper back to the testing company to see if they were cool with the new revisions.... It would add a whole new layer of waiting and review to an already long and frustrating process.
So I said no thanks and moved on to new projects. I suspect I'm not alone in this; grad students and pre-tenure professors, after all, have time constraints on how long the publication process can take, and that process is professionally crucial. Difficulties in obtaining data on these tests amounts to a powerful disincentive for conducting research on them, which in turn leaves us with less information about them than we should have, given the roles they play in our economy. Some of these testing companies are very good about doing rigorous research on their own products - ETS is notable in this regard - but I remain convinced that only truly independent validation can give us the confidence we need to use them, especially given the stakes for students.
As for the study - please be gentle. I was a second-semester PhD student when I put this together. I was still getting my sea legs in terms of writing research articles, and I hadn't acquired a lot of the statistical and research methods knowledge that I developed over the course of my doctoral education. This study is small-n, with only 50 observations, though the results are still significant to the .05 alpha that is typical in applied linguistics. Today I'd probably do the whole set of essays. I'd also do a full-bore regression etc. rather than just correlations. Still, I can see the genesis of a lot of my research interests in this article. Anyway, check it out if you're interested, and please bear in mind the context of this research.
*****
Lexical Diversity and Quality in L1 and L2 Student Essays
Introduction and Rationale.
Traditionally, linguistics has recognized a broad division within the elementary composition of any language: the lexicon of words, parts of words, and idiomatic expressions that make up the basic units of that language’s meanings, and the computational system that structures them to make meaning possible. In college writing pedagogy, our general orientation is to higher-order concerns than either of these two elementary systems (Faigley and Witte). College composition scholars and instructors are more likely to concern themselves with rhetorical, communicative, and disciplinary issues than in the two elementary systems, which they reasonably believe to be too remedial to be appropriate for college level instruction. This prioritization of higher-order concerns persists despite tensions with students, who frequently focus on lower-order concerns themselves (Beach and Friedrich). Despite this resistance, one half of this division receives considerable attention in college writing pedagogy. Grammatical issues are enough of a concern that research has been continuously published concerning how to address them. Books are published that deal solely with issues of grammar and mechanics. This grudging attention persists, despite theoretical and disciplinary resistance to it, because of a perceived exigency: without adequate skills in basic English grammar and syntax, writers are unlikely to fulfill any of the higher-order requirements typical of academic writing.
In contrast, very little attention has been paid— theoretically, pedagogically, or empirically— to the lexical development of adult writers. Consideration of vocabulary is dominantly concentrated in scholarly literature of childhood education. Here, the lack of attention is likely a combination of both resistance based on the assumption that such concerns are too rudimentary to be appropriate for college instruction, as with grammatical issues, and also because of a perceived lack of need. Grammatical errors, after all, are typically systemic— they stem from a misunderstanding or ignorance of important grammatical “moves,” which means they tend to be replicated within assignments and across assignments. A lack of depth in vocabulary, meanwhile, does not result in observable systemic failures within student texts. Indeed, because a limited vocabulary results in problems of omission rather than of commission, it is unlikely to result in identifiable error at all. A student could have a severely limited vocabulary and still produce texts that are entirely mechanically correct.
But this lack of visibility in problems of vocabulary and lexical diversity should not lead us to imagine that limited vocabulary does not represent a problem for student writers. Academic writing often functions as a kind of signaling mechanism through which students and scholars demonstrate basic competencies and shared knowledge that indicates that they are part of a given discourse community (Spack). Utilizing specialized vocabulary is a part of that. Additionally, writing instructors and others who will evaluate a given student’s work often value and privilege complexity and diversity of expression. What’s more, the use of an expansive vocabulary is typically an important element of the type of precision in writing that many within composition identify as a key part of written fluency.
Issues with vocabulary are especially important when considering second language (L2) writers. Part of the reason that most writing instructors are not likely to consider vocabulary as an element of student writing lies in the fact that, for native speakers of a given language, vocabulary is principally acquired, not learned. Most adults are already in possession of a very large vocabulary in their native language, and those who are not are unlikely to have entered college. For L2 writers, however, we cannot expect similar levels of preexisting vocabulary. Vocabulary in a second language, research suggests, is more often learned than acquired. The lexical diversity of a given L2 writer is likely influenced by all of the factors that contribute to general second language fluency, such as amount of prior instruction, quality of instruction, opportunities for immersion, exposure to native speakers, access to resources, etc. Further, because some L2 writers return to their country of origin, or otherwise frequently converse in their L1, they may lack opportunities to continue to develop their vocabulary equivalent to their L1 counterparts. In sum, the challenge of adequate vocabulary can reasonably be expected to be higher for L2 writers.
If it can be demonstrated that diversity in vocabulary in fact has a significant impact on perceptions of quality in student essays, we might be inspired to alter our pedagogy. Attention to development of vocabulary might be a necessary part of effective second language writing instruction. Such pedagogical evolution might entail formal vocabulary teaching with testing and memorization, or greater reading requirements, or any number of instruments to improve student vocabulary. But before such changes can be implemented, we first must understand whether diversity in vocabulary alters perceptions of essay quality and to what degree. This research is an attempt to contribute to that effort.
Theoretical Background.
The calculation of lexical diversity has proven difficult and controversial. The simplest method for measuring lexical diversity lies in simply counting the number of different words (NDW) that appear in a given text. (This figure is now typically referred to as types.) In some research, only words with different roots are counted, so that inflectional differences do not alter the NDW; in some research, each different type is counted separately. The problems with NDW are obvious. The figure is entirely dependent on the length of a given text. It’s impossible to meaningfully compare a text of 50 words to a text of 75 words, let alone to a text of 500 words or 3,000 words. Problems with scalability— the difficulty in making meaningful measures across texts of differing lengths— have been the most consistent issue with attempts to measure lexical diversity.
The most popular method to address this problem has been Type-to-Token Ratio, or TTR. TTR is a simple measurement where the number of types is divided by the number of tokens, giving a proportion between 0 to 1, with a higher figure indicating a more diverse range of vocabulary in the given sample. A large amount of research has been conducted utilizing TTR over a number of decades (see Literature Review). However, the discriminatory power of TTR, and thus its value as a descriptive statistic, has been seriously disputed. These criticisms are both empirical and theoretical in nature. Empirically, TTR has been shown in multiple studies to steadily decrease with sample size, making it impossible to use the statistic to discriminate between texts and thus losing any explanatory value (Broeder; Chen and Leimkhuler; Richards). David Malvern et al explain the theoretical reason for this observed phenomenon:
It is true that a ratio provides better comparability than the simple raw value of one quantity when the quantities in the ration come in fixed proportion regardless of their size. For example, in the case of the density of a substance, the ratio (mass/volume) remains the same regardless of the volume from which it is calculated. Adding half as much again to the volume will add half as much to the mass… and so on. Language production is not like that, however. Adding an extra word to a language sample always increases the token count (N) but will only increase the type count (V) if the word has not been used before. As more and more words are used, it becomes harder and harder to avoid repetition and the chance of the extra word being a new type decreases. Consequently, the type count (V) in the numerator increases at a slower rate than the token count (N) in the denominator and TTR inevitably falls. (22)
This loss of discriminatory power over sample size renders TTR an ineffective measure of lexical diversity. Many transformations of TTR have been proposed to address this issue, but none of them have proven consistently satisfying as alternative measures.
One of the most promising metrics for lexical diversity is D, derived from the vocd algorithm. Developed by Malvern et al, and inspired by theoretical statistics described by Thompson and Thompson in 1915, the process utilized in the generation of D avoids the problem of sample size through reference to ideal curves. The algorithm, implemented through a computer program, draws a set of samples from the target text, beginning with 35 types, then 36, etc., until 50 samples are taken. Each sample is then compared to a series of ideal curves that are generated based on the highest and lowest possible lexical diversity for a given text. This relative position, derived from the curve fitting, is expressed as D, a figure that represents rising lexical diversity as it increases. Since each sample is slightly different, each one returns a slightly different value for D, which is averaged to reach Doptimum. See Figure 1 for a graphical representation of the curve fitting of vocd.

Figure 1. “Ideal TTR versus token curves.” Malvern et al. Lexical Diversity and Language Development, pg. 52
D has proven to be a more reliable statistic than those based on TTR, and it has not been subject to sample size issues to the same degree as other measures of lexical diversity. (See Limitations, however, for some criticisms that have been leveled against the statistic.) The calculation of D and the vocd algorithm are quite complex and go beyond the boundaries of this research. An in-depth explanation and demonstration of vocd and the generation of D, including a thorough literature review, can be found in Malvern et al’s Lexical Diversity and Language Development (2004).
Research Questions.
My research questions for this project are multiple.
How diverse is the vocabulary of L1 and L2 writers in standardized essays, as operationalized through lexical density measures such as D?
What is the relationship between quality of student writing, as operationalized through essay rating, and the diversity of vocabulary, as operationalized through measures of lexical density such as D?
Is this relationship equivalent between L1 and L2 writers? Between writers of different first languages?
Literature Review.
As noted in the Rationale section, the consideration of diversity in vocabulary in composition studies generally and in second language writing specifically has been somewhat limited, at least relative to attention paid to strictly grammatical issues or to higher-order concerns such as rhetorical or communicative success. This lack of attention is interesting, as some standardized tests of writing that are important aspects of educational and economic success explicitly mention lexical command as an aspect of effective writing.
Some research has been conducted by second language researchers considering the importance of vocabulary to perceptions of writing quality. In 1995, Cheryl Engber published “The Relationship of Lexical Proficiency to the Quality of ESL Compositions.” This research involved the holistic scoring of 66 student essays and comparison to four measures of lexical diversity: lexical variation, error-free variation, percentage of lexical error, and lexical density. These measures considered not only the diversity of displayed vocabulary but also the degree to which the demonstrated vocabulary was used effectively and appropriately in its given context. Engber found that there was a robust and significant correlation between a student’s (appropriate and free of error) demonstrated lexical diversity and the rating of that student’s essay. However, the research utilized the conventional TTR measure for lexical diversity, which is flawed for the reasons previously discussed. In 2000, Yili Li published “Linguistic characteristics of ESL writing in task-based e-mail activities.” Li’s research considered 132 emails written by 22 ESL students, which addressed a variety of tasks and contexts. These emails were subjected to linguistic feature analysis, including lexical diversity, as well as syntactic complexity and grammatical accuracy. Li found that there were slight but statistically significant differences in the lexical diversity of different email tasks (Narrative, Information, Persuasive, Expressive). She also found that lexical diversity was essentially identical between structured and non-structured writing tasks. However, she too used the flawed TTR measure for lexical diversity. In the context of the period of time in which these researchers conducted their studies, the use of TTR was appropriate, but its flaws have eroded the confidence we can place in such research.
The most directly and obviously useful precedent for my current research was conducted by Guoxing Yu and published in 2009 under the title “Lexical Diversity in Writing and Speaking Task Performances.” Having been published within the last several years, Yu’s research is new enough to have assimilated and reacted to the many challenges to TTR and related measures of lexical diversity. Yu’s research utilizes D as measured via the vocd algorithm that also was used in this research. Yu also correlated D with essay rating. However, Yu’s research was primarily oriented towards comparing and contrasting written lexical diversity with spoken lexical diversity and the influence of each on perceptions of fluency or quality. My own research is oriented specifically towards written communication. Additionally, Yu’s research utilized essays that were written and rated specifically for the research, to approximate the type of essays typically written for standardized tests, but also understood more generally. My own research utilizes a data set of essays that were specifically written and rated within the administration of a real standardized test, [REDACTED] (see Research Subjects). Also in 2009, Pauline Foster and Parvaneh Tavakoli published a consideration of how narrative complexity affected certain textual features of complexity, fluency, and lexical diversity. Like Yu, Foster and Takavoli utilized D as a measure of lexical diversity. Among other findings, their research demonstrated that the narrative complexity of a given task did not have a significant impact on lexical diversity.
Research Subjects.
For this research, I utilized the [REDACTED] archive, a database of essays that were submitted for the writing portion of the [REDACTED]. These essays were planned and composed by test takers, in a controlled environment, in 30 minutes. These essays were then rated by trained raters working for [REDACTED], holistically scored between 1 (the worst score) and 6 (the best score). Essays which earned the same rating by each rater are represented in this research through whole numbers ending in 0 (10, 20, 30, 40, 50, 60). Essays where one rater gave one score and the other rater gave one point higher or lower are represented through whole numbers ending in 5 (15, 25, 35, 45, 55). Essays where the raters assigned scores that were discordant by more than a point were rescored by [REDACTED] and are not included in this sample. According to [REDACTED], the inter-rater reliability of the [REDACTED] averages .790. A detailed explanation of the test can be found in the [REDACTED].
The corpus utilized in this research includes 1,737 essays from test administrations performed in 1990. Obviously, the age of the data should give us pause. However, as the [REDACTED] writing section and standardized essay test writing have not undergone major changes in the time since then, I believe the data remains viable. (See Limitations for more.) Within the archive, test subjects are represented from four language backgrounds: English, Spanish, Arabic, and Chinese. The essays in the archive are derived from two prompts, listed below:
[REDACTED]
[REDACTED]
The [REDACTED] archive exists as a set of .TXT files that lack file-internal metadata. Instead, the essays are identified via a complex number, and the number compared against a reference list to find information on the essay topic, language background, and score. Because of this, and because of the file extension necessary for use with the software utilized in this research (see Methods), this study utilized a small subsample of 50 essays. For this reason, this research represents a pilot study. In order to control for prompt effects, all of the included essays are drawn from the second prompt, about the writer’s preferred method of news delivery. I chose 25 essays from L1 English writers and 25 essays from L1 Chinese writers, for an n of 50. Each set of essays represents a range of scores from across the available sample. Because the essays were almost all too short to possess adequate tokens to be measured by vocd, I eliminated essays rated 10. I drew five essays each at random from those rated 20, 30, 40, 50, and 60 from the Chinese L1s, for a total of 25 essays from Chinese writers. Because L1 English writers are naturally more proficient at a test of English, the English essays have a restricted range, with very few 10s, 20s, and 30s. I therefore randomly drew five essays each from those rated 35, 40, 45, 50, and 60, for a total of 25 essays from English writers.
Methods.
This research utilized a computational linguistic approach. Due to the aforementioned problems with traditional statistics for measuring lexical density like TTR and NDW, I used an algorithm known as vocd to generate D, the previously-discussed measure of lexical density that compares a random sample of given texts to a series of ideal curves to determine how diverse the vocabulary of that text is. This algorithm was implemented in the CLAN (Computerized Language Analysis) software suite, a product of the CHILDES (Child Language Development Exchange System) program at Carnegie Mellon University. CLAN is a freeware software that provides a graphical user interface (GUI) for using several programs for typical linguistics uses, such as frequency lists or collocation. Previously, researchers using vocd would have to perform the operations using a command line system. The integration of vocd into CLAN makes vocd easier to use and more accessible.
CLAN uses a proprietary form of file extension, .CHA, as the program suite was originally developed for the study of transcribed audio data that maintains information about pausing and temporal features. In order to utilize the [REDACTED] archive files, they were converted to .CHA format using CLAN’s “textin” program. They were then analyzed using the vocd program, which returned information on types (NDW), tokens (word count), TTR, and the various Ds obtained with each sample, along with a Doptimum derived by averaging each. An example of the output provided by CLAN is below in Figure 2.

Figure 2. CLAN Interface. Once these data were obtained, averages for type, token, TTR, and D were generated. Then, corrolation matrixes were developed for Chinese L1s, English L1s, and combined data, to find correlations between Types, Tokens, TTR, D, and rating. A scatter plot was developed from the combined data’s correlation of D and rating to represent that relationship graphically.
Results.
There are several relevant, statistically significant results from my research. Raw data is attached as Appendix A.
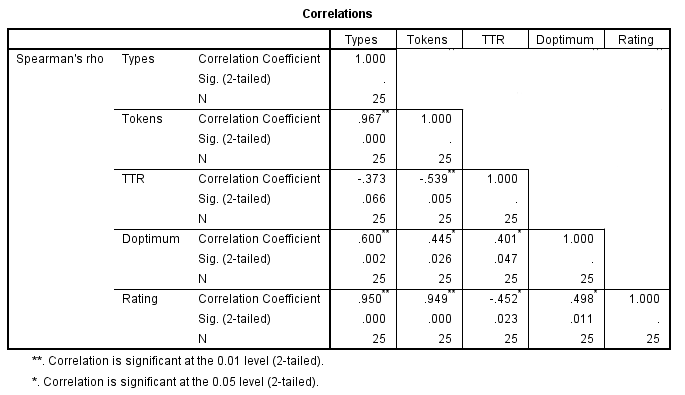
Figure 3. Chinese L1s Correlation Matrix
As can be seen in the correlation matrix of results from essays by Chinese L1 students (Figure 3), there is a moderate, significant correlation between D and an essay’s rating, at .498 and significant at p<.05. This suggests that, for Chinese L1s (and perhaps L2 students in general), the demonstration of diversity in vocabulary is an important part of perceptions of essay quality. The highest correlation are with the simple measures of length, type (NDW) and token (essay length). These correlations (while unusually high for this sample) confirm longstanding empirical understanding that length of essay correlates powerfully with essay rating in standardizd essay tests. The moderate negative correlation between TTR and tokens adds further evidence that TTR degrades with text length.
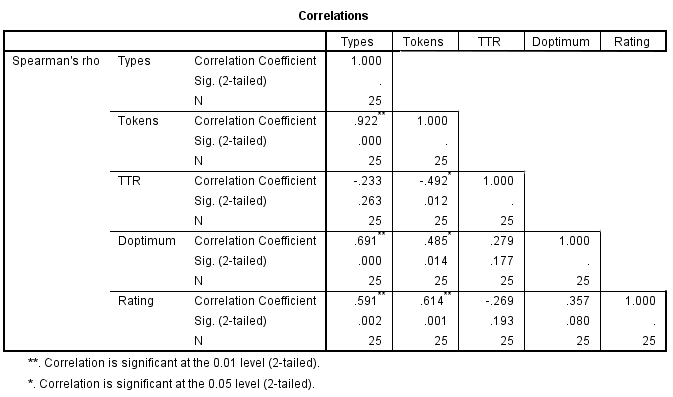
Figure 4. English L1s Correlation Matrix
The subsample of English L1s displays some similarities to the correlations found in Chinese L1s. Once again, there is a significant correlation between tokens (essay length) and rating, suggesting that writing enough remains an essential part of succeeding in a standardized essay test. The correlation between rating and D is somewhat smaller than that for Chinese L1s. This might perhaps owe to an assumed lower functional vocabulary for ESL students. We might imagine a threshold of minimum functional vocabulary usage that must be met before writers can demonstrate sufficient writing ability to score highly on a standardized essay test. If true, and if L1s are likely to be in possession of a vocabulary at least large enough to craft effective essay answers, lexical diversity could be more important at the lower end of the quality scale. This might prove true especially in a study with a restricted, negatively skewed range of ratings for L1 writers. More investigation is needed. Unfortunately, this correlation is not statistically significant, perhaps owing to the small sample size utilized in this research.
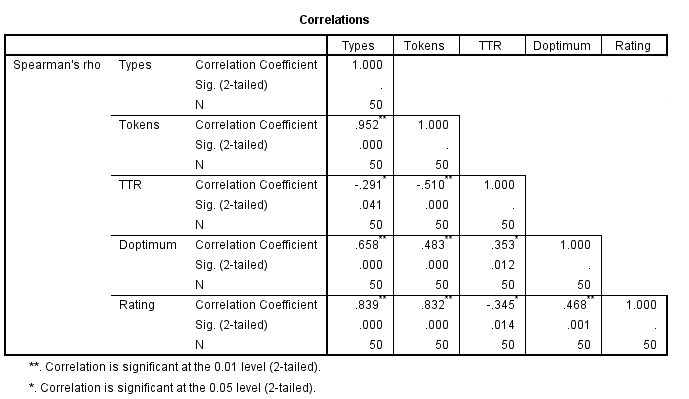
Figure 5. Combined Data Correlation Matrix.
The combined results show similar patterns, as is to be expected. These results are encouraging for this research. The moderate, statistically-significant (p<.01) correlaiton between rating and D demonstrates that lexical diversity is in fact an important part of student success at standardized essay tests. The high correlation between rating and both types and tokens confirms longstanding beliefs that writing a lot is the key to scoring highly on standardized essay tests. TTR’s negative correlation with tokens demonstrates again that it inevitably falls with text length; its negative correlation with rating demonstrates that it lacks value as a descriptive statistic that can contribute to understanding perceived quality.
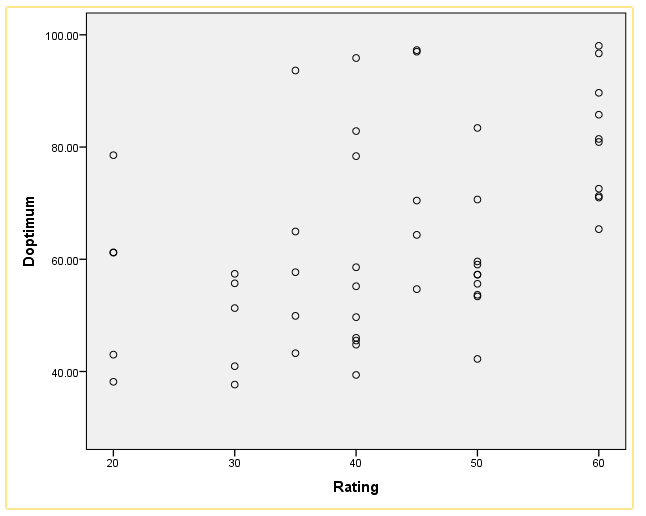
Figure 6. Scatterplot of Doptimum-Rating Correlation for Combined Data.
This scatterplot demonstrates the key correlation in this research, between D and essay rating. A general progression from lower left to upper right, with many outliers, demonstrates the moderate correlation I previously identified. This correlation is intuitively satisfying. As I have argued, a diverse functional vocabulary is an important prerequisite of argumentative writing. However, while it is necessary, it is not sufficient; essays can be written that display many different words, without achieving rhetorical, mechanical, or communicative success. Likewise, it is possible to write an effective essay that is focused on a small number of arguments or ideas, resulting in a high rating with a low amount of demonstrated diversity in vocabulary.
Limitations.
There are multiple limitations to this research and research design.
First, my data set has limitations. While the data set comes directly from [REDACTED], and represents actual test administrations, because I did not collect the data myself, there is a degree of uncertainty about some of the details regarding its collection. For example, there is reason to believe that the native English speaking participants (who naturally were unlikely to undertake a test of English language ability like the [REDACTED]) took the test under a research or diagnostic directive. While this is standard practice in the test administration world (Fulcher 185), it might introduce construct-irrelevant variance into the sample, particularly given that those taking the test on a diagnostic or research basis might feel less pressure to perform well. Additionally, the particular database of essays contains samples that are over 20 years old. Whether this constitutes a major limitation of this study is a matter of interpretation. While that lack of timeliness might give us pause, it is worth pointing out that neither the [REDACTED]'s writing portion or standardized tests of writing of the type employed in the [REDACTED] have changed dramatically in the time since this data was collected. The benefit of using actual data from a real standardized essay test, in my view, outweighs the downside of the age of that data. A final issue with the [REDACTED] archive as a dataset for this project lies in broad objections to the use of this kind of test to assess student writing. Arguments of this kind are common, and frequently convincing. However, exigence in utilizing this kind of data remains. Tests like the TOEFL, SAT, GRE, and similar high-stakes assessments of writing are hurdles that frequently must be cleared by both L1 and L2 students alike. High stakes assessments of this type are unlikely to go away, even given our resistance to them, and so should continue to be subject to empirical inquiry.
Additionally, while D does indeed appear to be a more robust, predictive, and widely-applicable measure of lexical diversity than traditional measures like NDW and TTR, it is not without problems. Recent scholarship has suggested that D, too, is subject to reduced discrimination above a certain sample size. See, for example, McCarthy and Jarvis (2007) use parallel sampling and comparison to a large variety of other indexes of lexical diversity to demonstrate that D’s ability to act as a unit of comparison degrades across texts that vary by more than perhaps 300 words (tokens). McCarthy and Jarvis argue that research utilizing vocd should be restricted to a “stable range” of texts comprising 100-400 words. The vast majority of essays in the TWE archive fall inside of this range, although many of the worst-scoring essays contain less than 100 words and a small handful exceed 400. Four essays in my sample do not meet the 100 word threshold, with word counts (tokens) of 51, 73, 86, and 90, and one essay that exceeds the 400 word threshold, with 428 words. Given the small number of essays outside of the stable range, I feel my research maintains validity and reliability despite McCarthy and Jarvis’s concerns.
Directions for Further Research.
There are many ways in which this research can be improved and extended.
The most obvious direction for extending this research lies in expanding its sample size. Due to the aforementioned difficulty in incorporating the [REDACTED] archive with the CLAN software package, less than 3% of the total [REDACTED] archive was analyzed. Utilizing all of the data set, whether through automation or by hand, is an obvious next step. An additional further direction for this research might involve the incorporation of additional advanced metrics for lexical diversity, such as MTLD and HD-D. In a 2010 article in the journal Behavior Research Methods titled “MTLD, vocd-D, HD-D: A validation study of sophisticated approaches to lexical diversity assessment,” Philip McCarthy and Scott Jarvis advocate for the use of those three metrics together in order to increase the validity of the analysis of lexical diversity. In doing so, they argue, these various metrics can help to address the various shortcomings of each other. There may, however, be statistical and computational barriers to affecting this kind of statistical analysis.
Another potential avenue for extending and improving this research would be to address the age of the essays analyzed by substituting a difference corpus of student essays for the [REDACTED]. This would also help with publication and flexibility of presentation, as ETS places certain restrictions on the use of its data in publication. Finding a comparable corpus will not necessarily be easy. While there are a variety of corpora available to researchers, few are as specific and real world-applicable as the [REDACTED] archive. Many publicly available corpora do not use writing specifically generated by student writers; those that do often derive their essays from a variety of tasks, genres, and assignments, limiting the reliability of comparisons made statistically. Finally, there are few extant corpora that have quality ratings already assigned to individual essays, as with the [REDACTED]. Without ratings, no correlation with D (or other measures of lexical diversity) is possible. Ratings could be generated by researchers, but this would likely require the availability of funds with which to pay them.
Finally, this research could be expanded by turning from its current quantitative orientation to a mixed methods design that incorporates qualitative analysis as well. There are multiple ways in which such an expansion might be undertaken. For example, a subsample of essays might be evaluated or coded by researchers who could assess them for a qualitative analysis of their diversity or complexity of vocabulary use. This qualitative assessment of lexical diversity could then be compared to the quantitative measures. Researchers could also explore individual essays to see how lexical diversity contributes to the overall impression of that essay and its quality. Researchers could examine essays where the observed lexical diversity is highly correlative with its rating, in order to explore how the diversity of vocabulary contributes to its perceived quality. Or they could consider essays where the correlation is low, to show the limits of lexical diversity of a predictor of quality and to better understand how outliers like this are generated.
Implications.
As discussed in the Introduction and Rationale statement, this research arose from exigence. I have identified a potential gap in instruction, the lack of attention paid to vocabulary in formal writing pedagogy for adult students. I have also suggested that this gap might be especially problematic for second language learners, who might be especially vulnerable to problems with displaying adequate vocabulary, and having access to correct terms, when compared to their L1 counterparts.
Given that this research utilized a data set drawn from a standardized test of English using time essay writing, and that many scolars in composition dispute the validity of such tests for gauging overall writing ability, the most direct implications of this study must be restricted to those tasks. In those cases, the lessons of this research appear clear: students should try to write as much as possible in the time alloted, and they should attend to their vocabulary both in order to fill that space effectively and to be able to demonstrate a complex and diverse vocabulary. Precise methods for this kind of self-tutoring or instruction are beyond the boundaries of this research, but both direct vocabulary instruction (such as with word lists and definition quizzes) and indirect (such as through reading challenging material) should be considered. As noted, this kind of evolution in pedagogy and best practices within instruction is at odds with many conventional assumptions about the teaching of writing. Some resistance is to be expected.
As for the broader notion of lexical diversity as a key feature of quality in writing, further research is needed. While this pilot study cannot provide more than a limited suggestion that demonstrations of a wide vocabulary are important to perceptions of writing quality, the findings of this research coincide with intuition and assumptions about how writing works. Further research, in keeping with the suggestions outline above, could be of potentially significant benefit to students, instructors, administrators, and researchers within composition studies alike.
Works Cited
Beach, Richard, and Tom Friedrich. "Response to writing." Handbook of writing research New York: The Guilford Press, 2006. 222-234. Print.
Broeder, Peter, Guus Extra, and R. van Hout. "Richness and variety in the developing lexicon." Adult language acquisition: Cross-linguistic perspectives. Vol. I: Field methods (1993): 145-163. Print.
Chen, Ye‐Sho, and Ferdinand F. Leimkuhler. "A type‐token identity in the Simon‐Yule model of text." Journal of the American Society for Information Science 40.1 (1989): 45-53. Print.
Engber, Cheryl A. "The relationship of lexical proficiency to the quality of ESL compositions." Journal of second language writing 4.2 (1995): 139-155. Print.
Faigley, Lester, and Stephen Witte. "Analyzing revision." College composition and communication 32.4 (1981): 400-414. Print.
Foster, Pauline, and Parvaneh Tavakoli. "Native speakers and task performance: Comparing effects on complexity, fluency, and lexical diversity." Language Learning 59.4 (2009): 866-896. Print.
“IELTS Handbook.” Britishcouncil.org; The British Council. 2007. Web. 1 May 2013.
Li, Yili. "Linguistic characteristics of ESL writing in task-based e-mail activities." System 28.2 (2000): 229-245. Print.
Malvern, David, et al. Lexical diversity and language development. New York: Palgrave Macmillan, 2004. Print.
McCarthy, Philip M., and Scott Jarvis. "vocd: A theoretical and empirical evaluation." Language Testing 24.4 (2007): 459-488. Print.
---. "MTLD, vocd-D, and HD-D: a validation study of sophisticated approaches to lexical diversity assessment." Behavior research methods 42.2 (2010): 381-392.
Richards, Brian. "Type/token ratios: What do they really tell us." Journal of Child Language 14.2 (1987): 201-209. Print.
Spack, Ruth. "Initiating ESL students into the academic discourse community: How far should we go?." Tesol quarterly 22.1 (1988): 29-51. Print.
“TOEFL IBT.” ets.org, The Educational Testing Service. nd. Web. 1 May 2013.
Yu, Guoxing. "Lexical diversity in writing and speaking task performances." Applied linguistics 31.2 (2010): 236-259. Print.
I read this fairly carefully and did not see any suggestion that D could correlate with grammar. It may be that the rating of the essay resulted more from grammar and spelling and that D is correlated to that.