


Study of the Week: What Actually Helps Poor Students? Human Beings

As I've said many times, a big part of improving our public debates about education (and, with hope, our policy) lies in having a more realistic attitude towards what policy and pedagogy are able to accomplish in terms of changing quantitative outcomes. We are subject to socioeconomic constraints which create persistent inequalities, such as the racial achievement gap; these may be fixable via direct socioeconomic policy (read: redistribution and hierarchy leveling), but have proven remarkably resistant to fixing through educational policy. We also are constrained by the existence of individual differences in academic talent, the origins of which are controversial but the existence of which should not be. These, I believe, will be with us always, though their impact on our lives can be ameliorated through economic policy.
I have never said that there is no hope for changing quantitative indicators. I have, instead, said that the reduction of the value of education to only those quantitative indicators is a mistake, especially if we have a realistic attitude towards what pedagogy and policy can achieve. We can and should attempt to improve outcomes on these metrics, but we must be realistic, and the absolute refusal of policy types to do so has resulted in disasters like No Child Left Behind. Of course we should ask questions about what works, but we must be willing to recognize that even what works is likely of limited impact compared to factors that schools, teachers, and policy don't control.
This week's Study of the Week, by Dietrichson, Bøg, Filges, and Jørgensen, provides some clues. It's a meta-analysis of 101 studies from the past 15 years, three quarters of which were randomized controlled trials. That's a particularly impressive evidentiary standard. It doesn't mean that the conclusions are completely certain, but that number of studies, particularly with randomized controlled designs, lends powerful evidence to what the authors find. If we're going to avoid the pitfalls of significance testing and replicability, we have to do meta-analysis, even as we recognize that they are not a panacea. Before we take a look at this one, a quick word on how they work.
Effect Size and Meta-Analysis
The term "statistically significant" appears in discussions of research all the time, but as you often hear, statistical significance is not the same thing as practical significance. (After "correlation does not imply causation!" that's the second most common Stats 101 bromide people will throw at you on the internet.) And it's true and important to understand. Statistical significance tests are performed to help ascertain the likelihood that a perceived quantitative effect is a figment of our data. So we have some hypothesis (giving kids an intervention before they study will boost test scores, say) and we also have the null hypothesis (kids who had the intervention will not perform differently than those who didn't take it). After we do our experiment we have two average test scores for the two groups, and we know how many of each we have and how spread out their scores are (the standard deviation). Afterwards we can calculate a p-value, which tells us the likelihood that we would have gotten that difference in average test scores or better even if the null was actually true. Stat heads hate this kind of language but casually people will say that a result with a low p-value is likely a "real" effect.
For all of its many problems, statistical significance testing remains an important part of navigating a world of variability. But note what a p-value is not telling us: the actual strength of the effect. That is, a p-value helps us have confidence in making decisions based on a perceived difference in outcomes, but it can't tell us how practically strong the effect is. So in the example above, the p-value would not be an appropriate way to report the size in the differences in averages between the two groups. Typically people have just reported those different averages and left it at that. But consider the limitations of that approach: frequently we're going to be comparing different figures from profoundly different research contexts and derived from different metrics and scales. So how can we responsibly compare different studies and through them different approaches? By calculating and reporting effect size.
As I discussed the other day, we frequently compare different interventions and outcomes through reference to the normal distribution and standard deviation. As I said, that allows us to make easy comparisons between positions on different scales. You look at the normal distribution and can say OK, students in group A were this far below the mean, students in group B were this far above it, and so we can say responsibly how different they are and where they stand relative the the norm. Pragmatically speaking (and please don't scold me), there's only about three standard deviations of space below and above the mean in normally-distributed data. So when we say that someone is a standard deviation above or below someone else, that gives you a sense of the scale we're talking about here. Of course, the context and subject matter makes a good deal of difference too.
There's lots of different ways to calculate effect sizes, though all involve comparing the size of the given effect to the standard deviation. (Remember, standard deviation is important because spread tells us how much we should trust a given average. If I give a survey on a 0-10 scale and I get equal numbers of every number on that scale - exactly as many 0s, 1s, 2s, 3s, etc. - I'll get an average of 5. If I give that same survey and everyone scores a 5, I still get an average of 5. But for which situation is 5 a more accurate representation of my data?) In the original effect size, and one that you still see sometimes, you simply divide the difference between the averages by the pooled standard deviations of the experiments you're comparing, to give you Cohen's d. There are much fancier ways to calculate effect size, but that's outside the bounds of this post.
A meta-analysis takes advantage of the affordances of effect size to compare different interventions in a mathematically responsible way. A meta-analysis isn't just a literature review; rather than just reporting what previous researchers have found, those conducting a meta-analysis use quantitative data made available to researchers to calculate pooled effect sizes. When doing so, they weight the data by looking at the sample size (more is better), the standardized deviation (less spread is better), and the size of the effect. There are then some quality controls and attempts to account for differences in context and procedure between different studies. What you're left with is the ability to compare different results and discuss how big effects are in a way that helps mitigate the power of error and variability in individual studies.
Because meta-analyses must go laboriously through explanations of how studies were selected and disqualified, as well as descriptions of quality controls and the particular methods to pool standard deviations and calculate effect sizes, reading them carefully is very boring. So feel free to hit up the Donation buttons to the right to reward your humble servant for peeling through all this.
Bet On the Null
One cool thing about meta-analysis is that they allow you to get a bird's eye view on the kind of effects that are reported on various studies of various types of interventions. And what you find, in ed research, is that we're mostly playing with small effects.
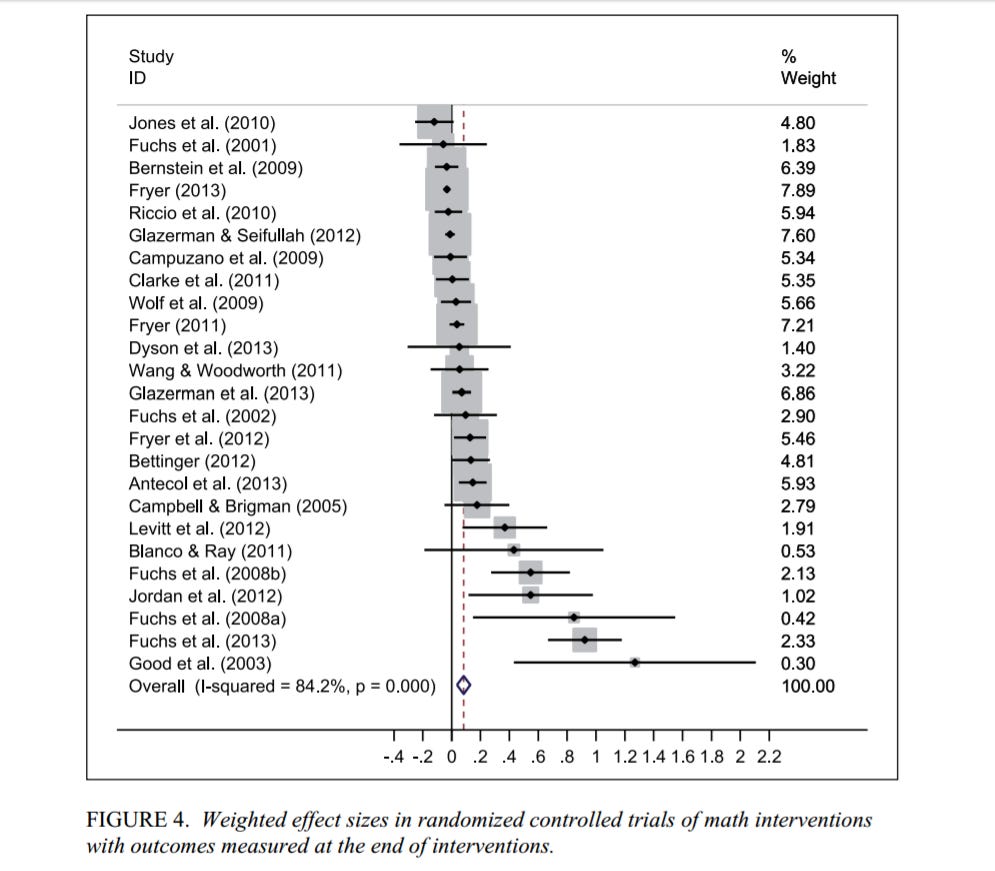
In the graphic above, the scale at the bottom is for effect sizes represented in standard deviations. The dots on the lines are the effect sizes for a given study. The lines extending from the dots are our confidence interval. A confidence interval is another way of grappling with statistical significance and how much we trust a given average. Because of the inevitability of measurement error, we can never say for 100% that a sample mean is the actual mean of that population. Instead, we can say with a certain degree of confidence, which we choose ourselves, that the true mean lines within a given range of values. 95% confidence intervals, such as these, are a typical convention. Those lines tell us that, given the underlying data, we can say with 95% confidence that the true average lies within those lines. If you wanted to narrow those lines, you could choose a lower % of confidence, but then you're necessarily increasing the chance the true mean isn't actually within the line.
Anyhow, look at the effects here. As is so common in education, we're generally talking about small impacts from our various interventions. This doesn't tell you what kind of interventions these studies performed - we'll get there in just a second - but I just want to note how studies with the most dependable designs tend to produce limited effects in education. In fact in a majority of these studies the confidence interval includes zero. Meanwhile, only 6 of these studies have meaningfully powerful effects, although in context they're pretty large.
Not to cast aspersions but the Good et al. study is the kind of effect size that makes me skeptical right off the bat. The very large confidence interval should also give us pause. That doesn't mean the researchers weren't responsible, or that we throw out that study entirely. It just means that this is exactly what meta-analysis is for: it helps us put results in context, to compare the quantitative results of individual studies against others and to get a better perspective on the size of a given effect and the meaning of a confidence interval. In this case, the confidence interval is so wide that we should take the result with several pinches of salt, given the variability involved. Again, no insult to the researchers; ed data is highly variable so getting dependable numbers is hard. We just need to be real: when it comes to education interventions, we are constrained by the boundaries of the possible.
Poor students benefit most from the intervention of human beings
OK, on to the findings. When it comes to improving outcomes for students from poor families, what does this meta-analysis suggest works?
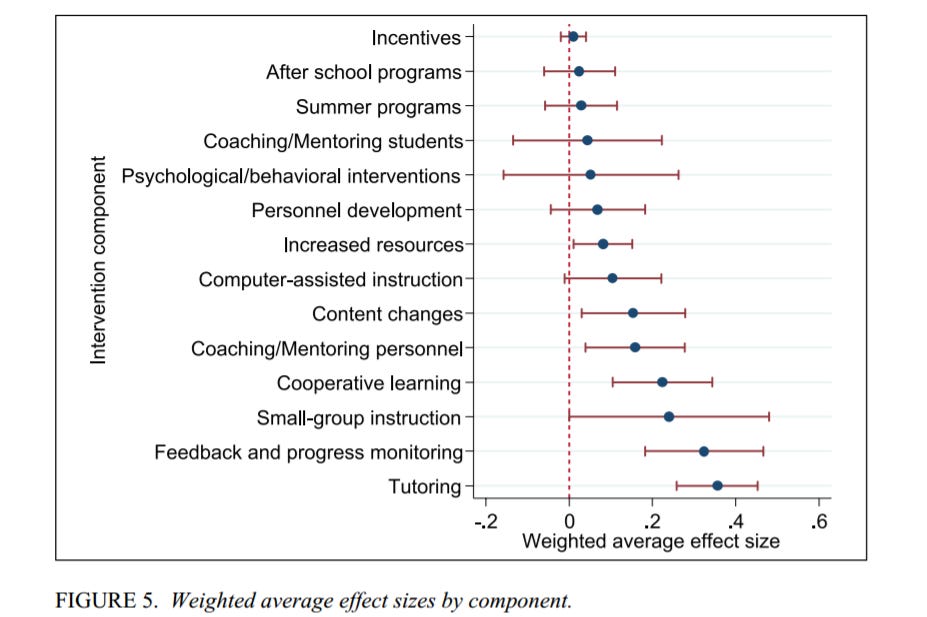
A few things here. We've got a pretty good illustration of the relationship between confidence intervals and effect size; small-group instruction has a strong effect size but because the confidence interval (just barely) overlaps with 0 it could not be considered statistically significant to a .05 level. Does that mean we throw out the findings? No; the .05 confidence interval isn't a dogma, despite what journal publishing guidelines might make you think. But it does mean that we have to be frank about the level of variability in outcomes here. It seems small group instruction is pretty effective in some contexts for some students but potentially not effective at all.
Bear in mind: because we're looking at aggregates of various studies here, wide confidence intervals likely mean that different studies found conflicting findings. We might say, then, that these interventions can be powerful but that we are less certain about the consistency of their outcomes; maybe these things work well for some students but not at all for others. Meanwhile an intervention like increased resources has a nice tight confidence interval, giving us more confidence that the effect is "real," but a small effect size. Is it worth it? That's a matter of perspective.
Tutoring looks pretty damn good, doesn't it? True, we're talking about less than .4 of a SD on average, but again, look at the context here. And that confidence interval is nice and tight, meaning that we should feel pretty strongly that this is a real effect. This should not be surprising to anyone who has followed the literature on tutoring interventions. Yet how often do you hear about tutoring from ed reformers? How often does it pop up at The Atlantic or The New Republic? Compare that to computer-mediated instruction, which is a topic of absolute obsession in our ed debate, the digital Godot we're all waiting for to swoop in and save our students. No matter how often we get the same result, technology retains its undeserved reputation as the key to fixing our system. When I say that education reform is an ideological project and not a practical one, this is what I mean.
What's shared by tutoring, small group instruction, cooperative learning, and feedback and progress monitoring - the interventions that come out looking best? The influence of another human being. The ability to work closely with others, particularly trained professionals, to go through the hard, inherently social work of error and correction and trying again. Being guided by another human being towards mastery of skills and concepts. Not paying tons of money on some ed tech boondoggle. Rather, giving individual people the time necessary to work closely with students and shepherd their progress. Imagine if we invested our money in giving all struggling students the ability to work individually or in small groups with dedicated educational professionals that we treated as respected experts and paid accordingly.
What are we doing instead? Oh, right. Funneling millions of dollars into one of the most profitable companies in the world for little proven benefit. Guess you can't be too cynical.