
restriction of range: what it is and why it matters

Let's imagine a bit of research that we could easily perform, following standard procedures, and still get a misleading result.
Say I'm an administrator at Harvard, a truly selective institution. I want to verify the College Board's confidence that the SAT effectively predicts freshman year academic performance. I grab the SAT data, grab freshmen GPAs, and run a simple Pearson correlation to find out the relationship between the two. To my surprise, I find that the correlation is quite low. I resolve to argue to colleagues that we should not be requiring students to submit SAT or similar scores for admissions, as those scores don't tell us anything worthwhile anyway.
Ah. But what do we know about the SAT scores of Harvard freshmen? We know that they're very tightly grouped because they are almost universally very high. Indeed, something like a quarter of all of your incoming freshman got a perfect score on the (new-now-old) 2400 scale. The reason your correlation is so low is that there simply isn't enough variation in one of your numbers to get a high metric of relationship. You've fallen victim to a restriction of range.
Think about it. When we calculate a correlation, we take pairs of numbers and see how one number changes compared to the other. So if I restrict myself to children and I look at age in months compared to height, I'm going to see consistent changes in the same direction - my observations of height at 6 months will be smaller than my observations at 12 months and those will in turn be smaller than at 24 months. This correlation will not be perfect, as different children are of different height and grow at different rates. The overall trend, however, will be clear and strong. But in simple mathematical terms, in order to get a high degree of relationship you have to have a certain range of scores in both numbers - if you only looked at children between 18 and 24 months you'd be necessarily restricting the size of the relationship. In the above example, if Harvard became so competitive that every incoming freshman had a perfect SAT score, the correlation between SAT scores and GPA (or any other number) would necessarily be 0.
Of course, most schools don't have incoming populations similar to Harvard's. Their average SAT scores, and the degree of variation in their SAT scores, would likely be different. Big public state schools, for example, tend to have a much wider achievement band of incoming students, who run the gamut from those who are competitive with those Ivy League students to those who are marginally prepared, and perhaps gained admission via special programs designed to expand opportunity. In a school like that, given adequate sample size and an adequate range of SAT scores, the correlation would be much less restricted - and it's likely, given the consistent evidence that SAT scores are a good predictor of GPA, significantly higher.
Note that we could also expect a similar outcome in the opposite direction. In many graduate school contexts, it's notoriously hard to get bad grades. (This is not, in my opinion, a problem in the same way that grade inflation is a potential problem for undergraduate programs, given that most grad school-requiring jobs don't really look at grad school GPA as an important metric.) With so many GPAs clustering in such a narrow upper band, you'd expect raw GRE-GPA correlations to be fairly low - which is precisely what the research finds.
Here's a really cool graphic demonstration of this in the form of two views on the same scatterplot. (I'm afraid I don't know where this came from, otherwise I'd give credit.)
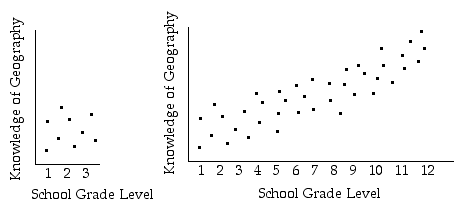
This really helps show restricted range in an intuitive way: when you're looking in too close at a small range on one variable, you just don't have the perspective to see the broader trends.
What can we do about this? Does this mean that we just can't look for these relationships when we have a restricted range? No. There are a number of statistical adjustments that we can make to estimate a range-corrected value for metrics of relationship. The most common of these, Thorndike's case 2, was (like a lot of stats formulas) patiently explained to me by a skilled instructor who guided me to an understanding of how it works which then escaped my brain in my sleep one night like air slowly getting let out of a balloon. But you can probably intuitively understand how such a correction would work in broad strokes - we have a certain data set restricted on X variable, the relationship is r strong along that restricted range, its spread is s in that range, so let's use that to guide an estimate of the relationship further along X. As you can probably guess, we can do so with more confidence if we have a stronger relationship and lower spread in the data that we do have. And there is a certain degree of range we have to have in our real-world data to be able to calculate a responsible adjustment.
There have been several validation studies of Thorndike's case 2 where researchers had access to both a range-restricted sample (because of some set cut point) and an unrestricted sample and were able to compare the corrected results on the restricted sample to the raw correlations on unrestricted samples. The results have provided strong validating evidence for the correction formula. Here's a good study.
There are also imputation models that are used to correct for range restriction. Imputation is a process common to regression when we have missing data and want to fill in the blanks, sometimes by making estimates based on the strength of observed relationships and spread, sometimes by using real values pulled from other data points.... It gets very complicated and I don't know much about it. As usual if you really need to understand this stuff for research purposes - get ye to a statistician!